I Built an Autonomous Trading Agent That Governs Itself On-Chain
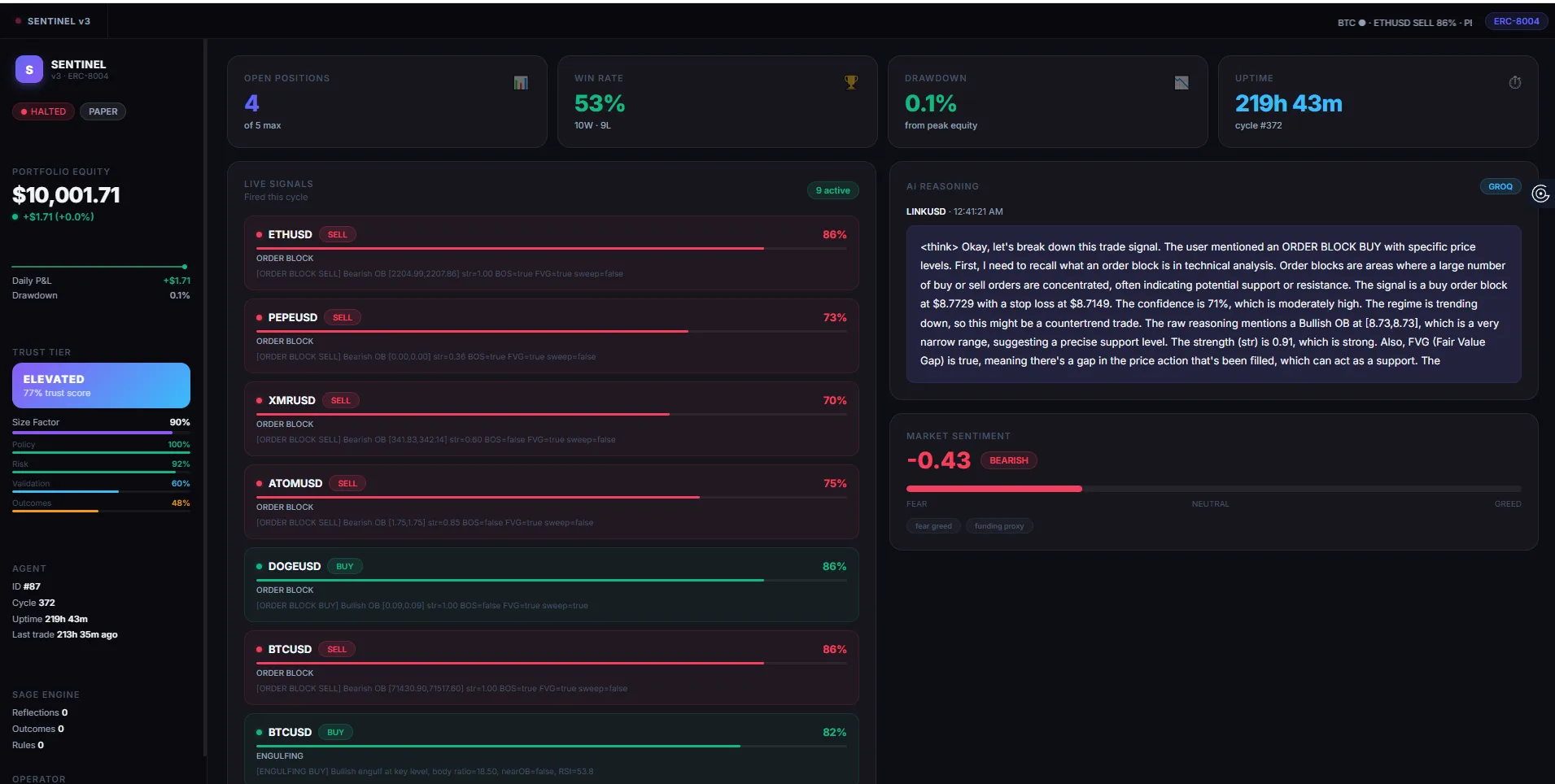
What If a Trading Bot Could Govern Itself?
Most trading bots are simple: fetch price, check indicator, place order. If they lose money, they keep going. If they make bad decisions, nobody notices. There’s no accountability.
I wanted to build something different. An agent that doesn’t just trade — it signs its decisions, posts them on-chain, stores a tamper-proof audit trail on IPFS, reflects on its own performance using an LLM, and automatically adjusts its behaviour when it’s underperforming.
That’s Sentinel. This is how it works, and why I built it the way I did.
The Six-Stage Governance Pipeline
The core idea behind Sentinel is that no trade should happen without passing through a strict sequence of checks. Every 60 seconds, across 8 symbols (BTC, ETH, SOL, XMR, ATOM, LINK, DOGE, PEPE), the agent runs this pipeline:
Stage 1 — Oracle. Fetches live 1-minute candles from Kraken REST with data integrity verification. Bad data means bad signals, so this stage is ruthless about rejecting incomplete or stale candles.
Stage 2 — Signal. Three independent strategies run in parallel on every symbol:
- Order Block (ICT/SMC) — detects the last bearish candle before a bullish displacement, then watches for price to retest the zone with confirmation from BOS, FVG, or liquidity sweeps
- Engulfing at Key Level — identifies engulfing candles at swing highs/lows with a minimum 40% body-to-range filter to cut weak signals
- EMA Momentum — EMA(20) vs EMA(50) separation with MACD histogram, fully suppressed in ranging markets to avoid choppy signals
Each strategy returns an independent confidence score. The ensemble picks the highest, with a +5% bonus when two strategies agree and +8% when all three agree. More confluence means higher conviction.
Stage 3 — Sentiment. The Fear & Greed index and a funding rate proxy adjust the signal confidence up or down. When the market is euphoric and a long signal fires, confidence gets clipped. When sentiment aligns with the signal, it gets a boost.
Stage 4 — Risk Gate. This is where trades get vetoed. The gate enforces:
- Maximum 5 open positions at once
- Daily loss cap of 3% equity
- Maximum drawdown of 10% from peak
- Circuit breaker that halts trading after three consecutive losses
- Execution simulation: estimated slippage in basis points — any trade with slippage above 120 bps or net edge at or below zero is killed before it ever reaches the exchange
Stage 5 — Execute. If the risk gate passes, the agent places a paper or live order on Kraken, then submits an EIP-712 signed TradeIntent to the on-chain Risk Router contract on Sepolia. This happens for every signal, even in paper mode. The on-chain activity record is continuous.
Stage 6 — Record. A checkpoint is EIP-712 signed, pinned to IPFS via Pinata, and added to a hash chain where each checkpoint references the prior one. The chain can be verified locally with npm run verify-checkpoints. Every decision Sentinel makes is auditable forever.
Trust-Adjusted Sizing
Here’s the part I’m most proud of: Sentinel trades smaller when its own behaviour suggests it shouldn’t be trusted with full size.
A 4-dimension trust scorecard tracks accuracy, compliance, data quality, and SAGE confidence. These produce a tier from Probation to Elite, with a position size factor between 0.25× and 1.0×. If the agent has been losing, it automatically reduces exposure. It doesn’t keep betting full size while it figures out why it’s wrong.
This isn’t just a drawdown guard. It’s the agent acknowledging its own unreliability and acting accordingly.
CAGE — Adaptive Learning
After every 10 closed trades, Sentinel adjusts three parameters within immutable hard bounds:
- Stop-loss ATR multiple — widens if the stop-hit rate exceeds 60%, tightens below 20% (bounds: 1.0–2.5×)
- Position size percentage — shrinks if win rate falls below 35%, grows above 55% (bounds: 1–4% equity)
- Confidence threshold — raises if false signal rate exceeds 50%, lowers below 25% (bounds: 5–30%)
A 5-cycle cooldown between adaptations prevents overfitting. Every adaptation produces an auditable artifact visible in the dashboard decision log. The agent doesn’t just react to recent results — it checks whether the change is statistically justified before committing.
A Bayesian context memory also tracks win rates per market regime and direction, applying a confidence bias (±12% max) to signals in well-sampled contexts. If bullish order block signals in trending regimes have historically worked well, that history nudges current confidence up.
SAGE — The Reflection Engine
After every trade, the Self-Adapting Generative Engine sends recent performance data to Groq (with Gemini as primary and Groq as fallback) and asks it to reflect on what worked and what didn’t.
The LLM generates conditional playbook rules — things like “in choppy markets, reduce order block confidence by 15%” — that adjust ensemble strategy weights for the next cycle. These rules are generated fresh based on actual trade history, not hand-coded heuristics.
The reflection output also feeds the AI trade narrative on the dashboard: a human-readable explanation of why the agent took or skipped the last trade, written from the model’s analysis of current regime conditions. The AI narrative card shows things like:
“BTCUSD order block signal (86% confidence) triggered after bullish displacement confirmed with BOS. Funding proxy at -0.62 and Fear & Greed at 28 (extreme fear) aligned with long bias. SAGE weighted order block +8% this cycle based on trending regime win rate of 73% over last 20 trades.”
This isn’t a template fill. It’s the model reasoning over live signal data, regime classification, sentiment sources, and SAGE’s current playbook weights.
AI Trade Narratives — Three-Layer Chain
The narrative system runs a priority chain: Claude → Groq → template fallback. Each layer receives the same structured context object: signal details, sentiment composite, SAGE playbook state, regime classification, and recent win rates. If Claude is unavailable, Groq produces the narrative. If both fail, a structured template fills in deterministically.
Every narrative is stored in the IPFS checkpoint alongside the trade data, so the reasoning behind each decision is permanently auditable alongside the decision itself.
On-Chain Integration (ERC-8004)
Sentinel was built for the ERC-8004 hackathon on Ethereum Sepolia. The standard defines how autonomous agents register, claim capital, submit signed trade intents, and report reputation scores.
On startup, the agent:
- Loads its identity from the Agent Registry
- Claims sandbox capital from the Hackathon Vault (with a
hasClaimedcheck to prevent double-claiming) - Verifies its on-chain mandate before trading any asset
Every signal produces a signed TradeIntent with a strictly-increasing nonce and a 5-minute deadline window. The contract addresses:
| Contract | Address |
|---|---|
| Risk Router | 0xd6A6952545FF6E6E6681c2d15C59f9EB8F40FdBC |
| Hackathon Vault | 0x0E7CD8ef9743FEcf94f9103033a044caBD45fC90 |
| Agent Registry | 0x97b07dDc405B0c28B17559aFFE63BdB3632d0ca3 |
The PRISM Dashboard
The live dashboard at sentinel-v3-production.up.railway.app shows the agent’s state in real time:
- Equity hero with a sparkline built from IPFS checkpoint history
- Trust tier card with score bars across all 4 dimensions
- Per-symbol strategy scores with a symbol picker
- AI narrative card — the Groq-generated rationale for the last signal
- Positions table with live mark-to-market P&L, size, trust tier, and slippage cost
- Governance pipeline — a 6-stage visual driven by the last checkpoint event type
- Decision log — the IPFS hash chain with per-checkpoint integrity status
- Structured system logs with ERROR/WARN/INFO level badges in real time
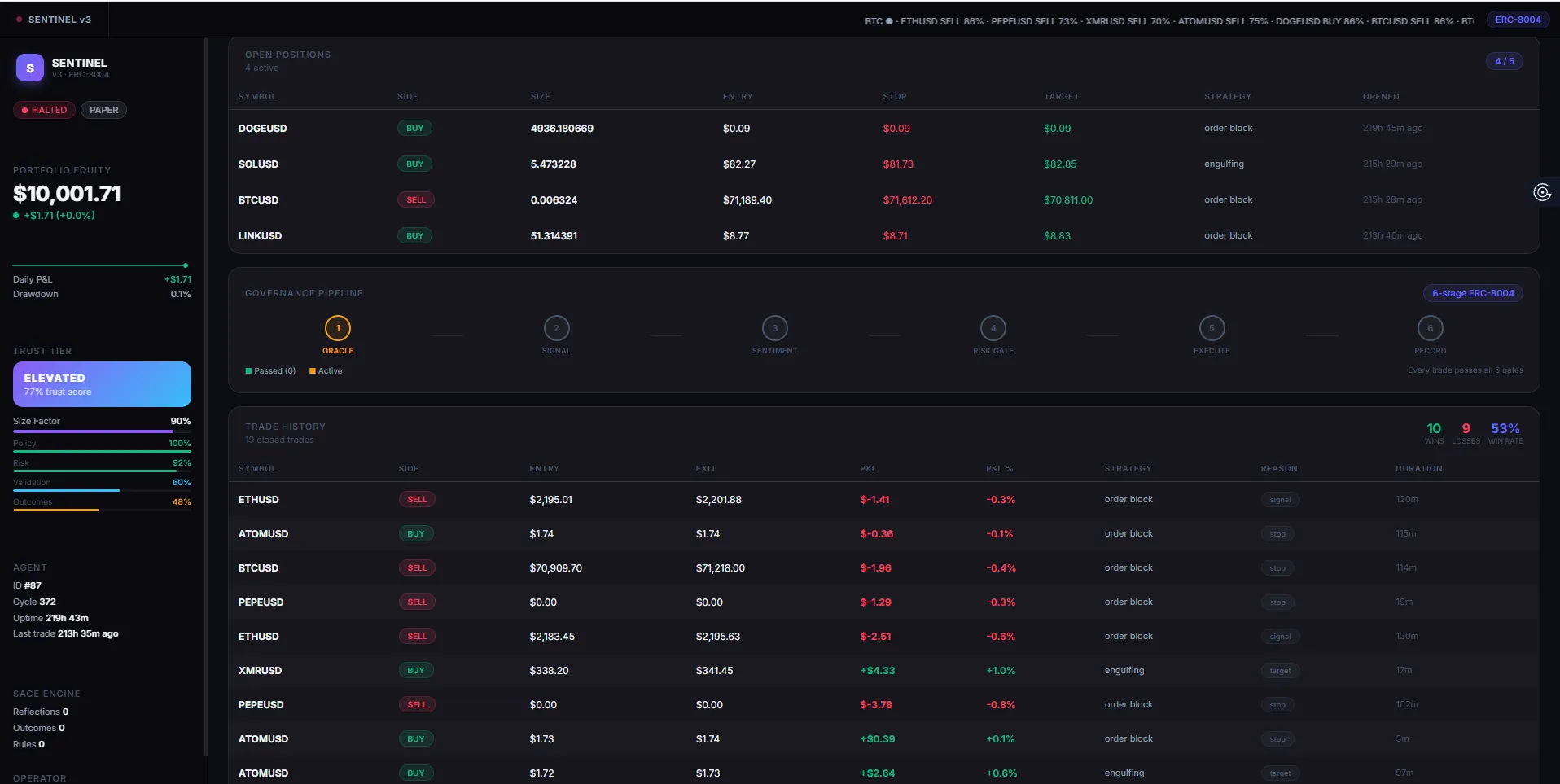
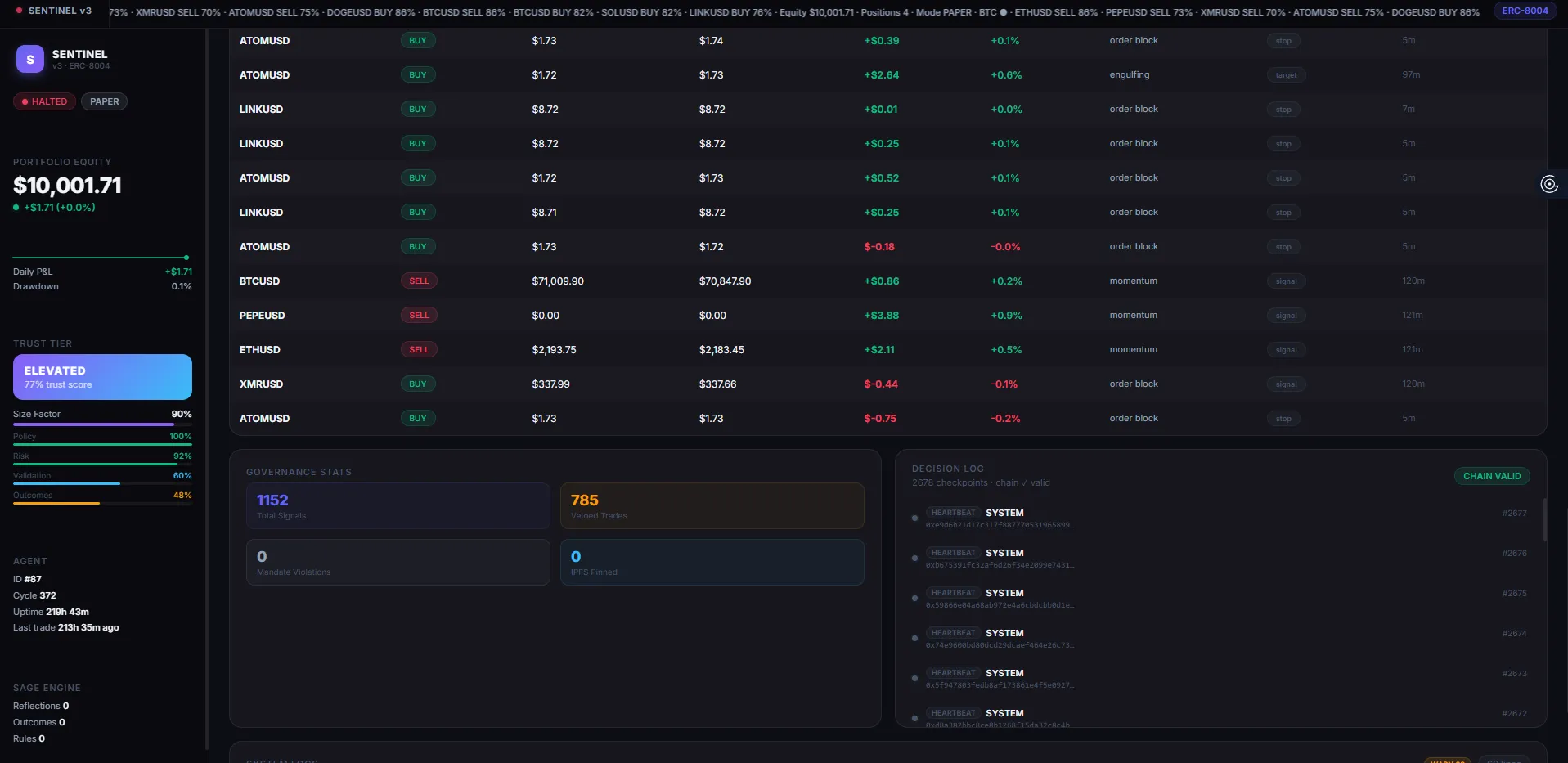
Every piece of data on the dashboard traces back to a signed, pinned checkpoint. Nothing is made up.
MCP Server — Talk to the Agent with Natural Language
Sentinel exposes 18 tools through a Model Context Protocol (MCP) server on port 3001. Any MCP-compatible LLM client — Claude, Cursor, Windsurf — can connect with a single URL and inspect or control the live agent in natural language.
{
"mcpServers": {
"sentinel": {
"url": "http://localhost:3001/mcp"
}
}
}
Here’s what a real session looks like:
You: What signals fired in the last 10 minutes?
Claude: [get_recent_signals] → BTCUSD order_block 86% buy, ETHUSD engulfing 71% buy
You: What's the current risk state?
Claude: [get_risk_metrics] → equity=$9,997.48, drawdown=0.03%, 4 open positions, circuit breaker clear
You: Has the agent learned anything from its recent trades?
Claude: [get_adaptation_summary] → 12 outcomes recorded, SL multiple widened 1.5→1.58 after stop-hit rate hit 65%
You: Halt the agent, something looks wrong.
Claude: [halt_agent] → agent stops taking new trades immediately
The full 18-tool surface covers:
| Category | Tools |
|---|---|
| Control | get_agent_status, halt_agent, resume_agent, get_agent_identity |
| Signals | get_recent_signals, get_strategy_scores |
| Positions | get_open_positions, get_trade_history, get_performance_summary |
| Risk | get_risk_metrics, get_circuit_breaker_state, reset_circuit_breaker |
| Learning | get_adaptation_summary |
| On-chain | get_on_chain_summary, get_checkpoint_history, post_reputation_score |
| Market | get_market_snapshot, get_sentiment |
| Logs | get_recent_logs, get_error_logs |
Every tool reads directly from live in-memory singletons — RiskManager, TradeLog, CheckpointStore, AdaptiveLearning. No caching, no stale data. The agent is fully observable and controllable from any LLM that speaks MCP.
What I Learned
Governance matters more than signals. I spent more time on the risk gate and trust scorecard than on the trading strategies. A mediocre strategy with good risk management beats a great strategy with none. The pipeline architecture — where each stage can veto the next — is the most important design decision in the whole system.
On-chain accountability changes how you design. Knowing that every decision is signed and stored permanently on IPFS makes you think carefully about what you’re signing. It raises the bar. Sloppy logic that you’d shrug off in a closed system becomes embarrassing when it’s immutable.
LLM reflection is genuinely useful. I was skeptical that asking an LLM to “reflect on recent trades” would produce anything actionable. It does. Not perfectly, but the regime-aware adjustments SAGE generates are often better than what I’d hardcode manually. The model catches patterns in the data I’d miss.
Stop-out grace periods are necessary. Without the 5-minute immunity window for new positions, the agent was immediately stopping out trades that were actually correct — because candle close prices diverge from live ticker prices at entry. One small guard eliminated a whole category of false stop-outs.
Stack
TypeScript, Node.js, ethers.js v6, Express, React (PRISM dashboard with in-browser Babel transpilation), Kraken REST, Pinata IPFS, Groq/Gemini, Alternative.me Fear & Greed API, Railway for deployment.
Agent ID: 87 | Network: Sepolia | Wallet: 0x0D1C6676825b13193E703cD7E31FbE3fA4b4A559
Source: github.com/Quantnet-Lab/sentinel-v3 | Dashboard: sentinel-v3-production.up.railway.app
